Magic Of Consistent Hashing
What is hashing?
Hashing is a way to transform any arbitrary string of data to a number in a defined range, using a mathematical function called as hash function. If you pass some data/object to a hash function, the output produced is called the hash of that data. For the same input, the hash value will always be the same. Hash values are typically used as lookup keys for storing and searching data in a cache.
Hashtable
Hashtable is a data structure that stores key value pairs. Hash value of the data is used as key to store the data. Hashtable provides two basic functions:
- set(key, data)
- get(key)
Ideally in a hashtable, a memory location or bucket (identified by key) will store only one value. But since two inputs can produce same hash value, it may lie in the same bucket in the form of a linked list. This might also happen when memory is limited and we carry out hash modulus N(= no. of buckets), for storing objects. Hash table offers fast searching of data since a bucket can be located by hashing the data to be searched and accessing the location in O(1)
Distributed Hashtable
Since a single machine has limited memory , we cannot store all the data in one hashtable if there millions or billions of records. We must distribute the data into multiple hashtables on different machines which is then called a distributed hash table (DHT) . Each machine or node holds a part of the data only. The challenge then becomes to decide which node would be responsible for storing a given object and how to find out the machine containing a given object for retrieval.
Typically the hash will be computed for the data and then hash modulus N(=no. of nodes) will be computed and the result will indicate which node the data goes to. Let’s take below example assuming our hash function output range is 0–255
| Data | Hash | Hash mod N(=4) | Node |
|---|---|---|---|
| John | 200 | 0 | node1 |
| William | 50 | 2 | node3 |
| Joe | 103 | 3 | node4 |
| Suzan | 81 | 1 | node2 |
Problems with Distributed Hashtable
As long as the number of servers or nodes in a DHT does not change, everything is fine. But if some nodes are removed or added, then there is a problem. To understand this, let’s try to remove node4 from our example. The new mapping will now look like below:
| Data | Hash | Hash mod N(=3) | Node |
|---|---|---|---|
| John | 200 | 1 | node2 |
| William | 50 | 2 | node3 |
| Joe | 103 | 1 | node2 |
| Suzan | 81 | 0 | node1 |
Do you see the problem? Not only do we have to remap the data of node4 (“Joe”) to a different node (node2) but the location of the other objects (“John” & “Suzan”) have also changed. If a client now tries to find the data from the cache, it will not be able to do so. So the mod N formula does not seem to be efficient since it changes the location of almost all the keys when N changes. Let’s try to solve this problem using another approach.
Consistent Hashing
Consistent hashing minimizes the number of objects affected due to change in the number of nodes in DHT. Consistent hashing works by creating a hash ring or a circle which holds all hash values in the range in the clockwise direction in increasing order of the hash values. Important thing is that the nodes (eg node IP or name) & the data both are hashed using the same hash function so that the nodes also become a part of this hash ring.
Storing data using consistent hashing
Every node in the hash ring is the owner of a range of hash values, lower bound being the previous node’s hash value (exclusive) and the upper bound being the hash value of the node itself (inclusive). Any data whose hash value is between this range get stored on this node. Let’s try to store the data in our example in the hash ring.
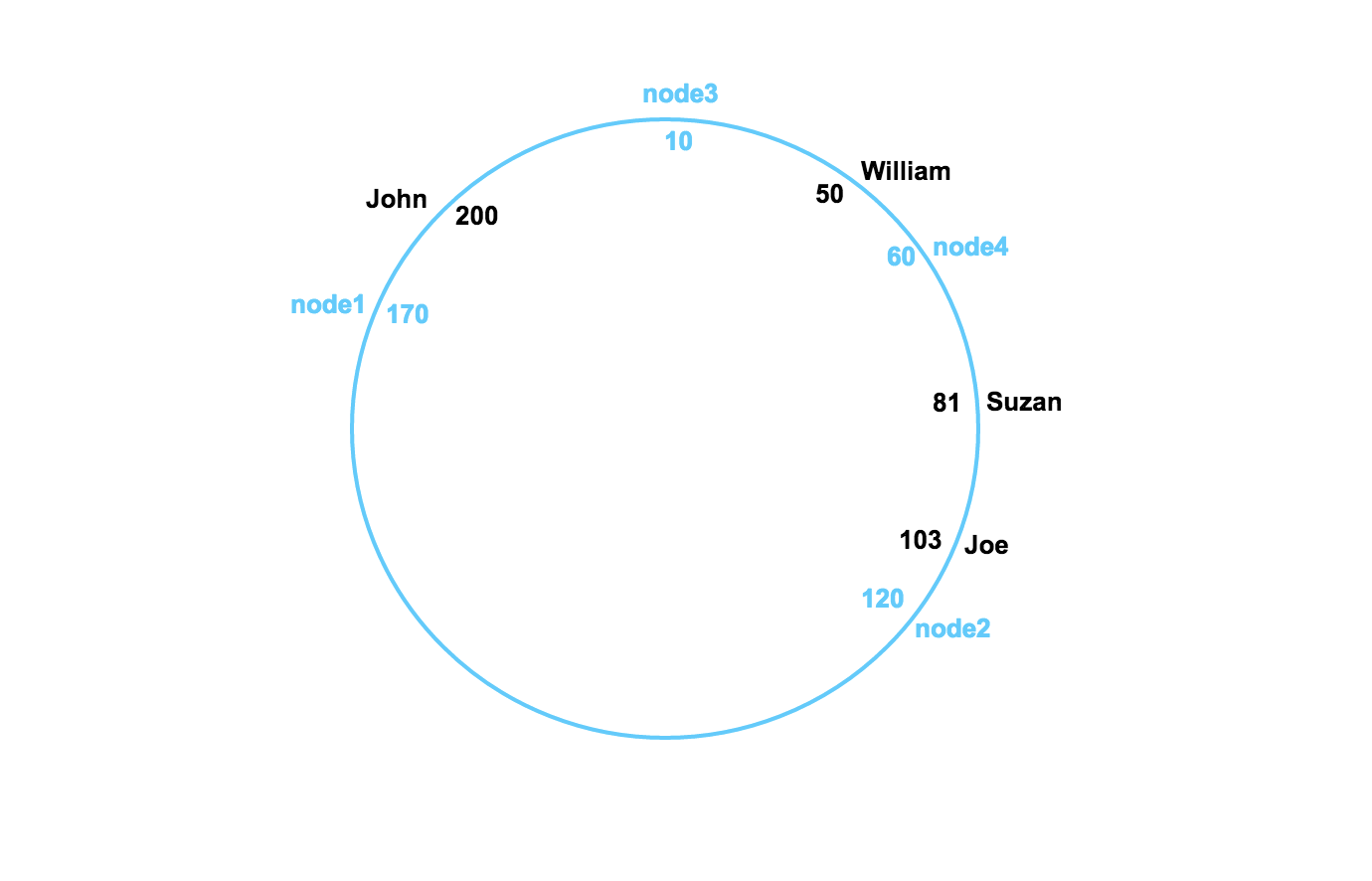
node3 holds all the data with hash values 171–10, node4 holds all data with hash values 11–60 and so on. So now our data is stored like below:
| Data | Hash | Node |
|---|---|---|
| John | 200 | node3 |
| William | 50 | node4 |
| Joe | 103 | node2 |
| Suzan | 81 | node2 |
Now, lets try to remove node3. The data object “John” now has to be stored to node4 while the data of the other nodes do to not change.
Building a Consistent Hash Ring
Below code is an example of how to build a consistent hash ring. I’ve used Murmur hash library to compute the integer hash of the data & the nodes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
const murmurhash = require('murmurhash');
class Node {
constructor(hash, name) {
this.hash = hash;
this.name = name;
}
}
class HashRing {
constructor() {
this.hashRing = [];
}
addNode(name) {
const hash = murmurhash.v3(name);
const node = new Node(hash, name);
if(this.hashRing.length == 0) {
this.hashRing[0] = node;
} else {
//if the hash is larger than any of the existing values, store it the end of the array
if(hash > this.hashRing[this.hashRing.length - 1].hash) {
this.hashRing.push(node);
} else {
//locate the immediate node whose hash is larger than the new node's hash. Then insert the new node here
const index = this.locateNode(name);
this.hashRing.splice(index, 0, node);
}
}
}
removeNode(name) {
const index = this.locateNode(name);
this.hashRing.splice(index, 1);
}
/*
modified binary search algorithm to find the very first node
whose hash value is greater then the input data hash.
The data can then be stored into that node.
*/
locateNode(data) {
const hash = murmurhash.v3(name);
if(hash > this.hashRing[this.hashRing.length - 1].hash) {
return 0;
}
let high = this.hashRing.length - 1, low = 0, mid;
let previous = (low + high) >> 1;
while (low <= high) {
mid = (low + high) >> 1;
if(hash == this.hashRing[mid].hash) {
return mid;
}
if(hash > this.hashRing[mid].hash && hash <= this.hashRing[previous].hash) {
return previous;
}
if(hash < this.hashRing[mid].hash && hash >= this.hashRing[previous].hash) {
return mid;
}
if (hash > this.hashRing[mid].hash) {
low = mid + 1;
} else {
high = mid - 1;
}
previous = mid;
}
}
test() {
this.addNode("node1")
this.addNode("node2")
this.addNode("node3")
this.addNode("node4")
this.addNode("node5")
this.addNode("node6")
let data = ["William","Suzan", "Joe", "John"];
for(const d of data) {
const ownerNode = this.hashRing[this.locateNode(d)];
console.log(`owner of ${d} is ${ownerNode.name}`);
}
}
}
const hashRing = new HashRing();
hashRing.test();
/*
OUTPUT:
owner of William is node1
owner of Suzan is node4
owner of Joe is node3
owner of John is node1
*/
Problems with Consistent hashing
As you can see in the above code output, “William” & “John” both end up mapping to node1 while the node2,5,6 are empty. This is because node hash values are random, so the distance between the adjacent nodes are not uniform resulting in some nodes storing relatively large number of objects compared to other nodes. This is inefficient since this means some of the nodes will be over utilized while some others will be under utilized. Let’s solve this problem by using the concept of virtual nodes.
Virtual Nodes
Virtual nodes are a way to distribute data in the DHT nodes more evenly. This is done by adding labels to the physical nodes and then computing the hash. For eg, you can create 10 vnodes for every node in the hash ring by looping through i=0 to 9 and finding the hash value of the (node + i) data. This will put the hashes at different places in the hashring and will allow more even distribution. More the number of vnodes, more uniform the distribution will be.
Replication
Since any node can fail in production, we must store a copy of the data to other nodes as well. Typically the data is replicated to the adjacent nodes of a given node since when the node goes down, based on our algorithm, the next immediate neighbour will be picked for fetching the data. The number of nodes used to store the copy of the data is called the replication factor. eg if replication factor=4, then next 4 adjacent nodes of a given node will be used to store a copy of the data.
Conclusion
Consistent hashing is an excellent way of retrieving the data when we want to build a fault tolerant scalable distributed system for data storage. Many applications like Apache Cassandra, Couchbase etc use consistent hashing at their core for this purpose.